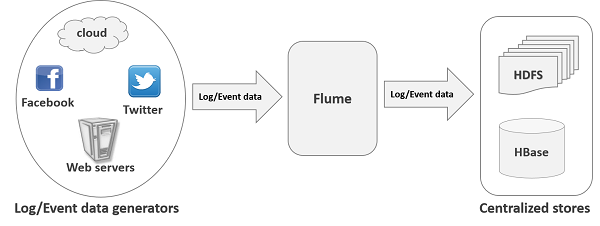
Trong bài trước đã hướng dẫn sử dụng Hive phân tích dữ liệu chứng khoán. Trong ví dụ đó, tôi sử dụng lệnh “load data local inpath” để đưa dữ liệu từ thư mục lưu trữ trên máy local vào tảng dữ liệu đã được tạo sẵn trong hive. Lệnh trên cũng đồng thời tạo thư mục NYSE trong workspace của Hive trên HDFS. Với lệnh trên, tôi phân vân rằng liệu với dữ liệu streaming (sử dụng Apache Flume liên tục đẩy dữ liệu vào HDFS) thì làm thế nào để Hive có thể đọc được (dữ liệu mới được tự động đẩy vào Hive table để phân tích). Rất may Hive đã làm cho tôi việc này. Để hiểu rõ hơn cơ chế đọc dữ liệu của Hive, tôi đã test một trường hợp sau: